
Java集合之HashMap源码分析
一、HashMap简介
HashMap是基于哈希表的Map接口实现的,它存储的是内容是键值对<key,value>映射。此类不保证映射的顺序,假定哈希函数将元素适当的分布在各桶之间,可为基本操作(get和put)提供稳定的性能。
ps:本文中的源码来自jdk1.8.0_45/src。
1、重要参数
HashMap的实例有两个参数影响其性能。
初始容量:哈希表中桶的数量
加载因子:哈希表在其容量自动增加之前可以达到多满的一种尺度
当哈希表中条目数超出了当前容量*加载因子(其实就是HashMap的实际容量)时,则对该哈希表进行rehash操作,将哈希表扩充至两倍的桶数。
Java中默认初始容量为16,加载因子为0.75。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 static final float DEFAULT_LOAD_FACTOR = 0.75f;
2、HashMap的继承关系
HashMap实现了Coneable接口,能被克隆,实现了Serializable接口,因此它也支持序列化。
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
二、hashMap源码分析
1、数据结构
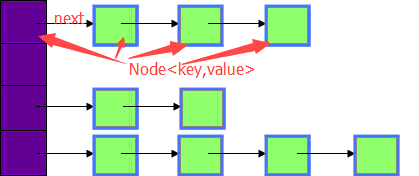
HashMap实际是一个链表的数组结构,当新建一个HashMap时,就会初始化一个数组。
/** * The table, initialized on first use, and resized as * necessary. When allocated, length is always a power of two. * (We also tolerate length zero in some operations to allow * bootstrapping mechanics that are currently not needed.) */ transient Node<K,V>[] table;
数组的类型为Node<K,V>,定义如下:
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; //next指定链表中下一个实例 Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } .... }
可以看到,Node就是数组中的元素,而每一个Map.Node就是一个key-value对,它还持有指向下一个元素的引用,这样就构成了链表。简单的构造图如下所示:
2、构造函数
HashMap有四个构造函数,代码如下:
//1.构造一个带指定初始容量和加载因子的空HashMap public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity); } //2.构造一个带指定初始容量和默认加载因子(0.75)的空 HashMap public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); } //3.构造一个具有默认初始容量 (16)和默认加载因子 (0.75)的空 HashMap public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted } //4.构造一个映射关系与指定 Map相同的新 HashMap public HashMap(Map<? extends K, ? extends V> m) { this.loadFactor = DEFAULT_LOAD_FACTOR; putMapEntries(m, false); }
3、HashMap常用方法
void clear():从此映射中移除所有映射关系
public void clear() //清空HashMap,将数组所有元素置为null { Node<K,V>[] tab; modCount++; if ((tab = table) != null && size > 0) { size = 0; for (int i = 0; i < tab.length; ++i) tab[i] = null; } }
Object clone():返回此 HashMap 实例的浅表副本
public Object clone() { HashMap<K,V> result; try { result = (HashMap<K,V>)super.clone(); //调用父类clone方法 } catch (CloneNotSupportedException e) { // this shouldn't happen, since we are Cloneable throw new InternalError(e); } result.reinitialize(); //初始化 result.putMapEntries(this, false); //将此HashMap元素放入result中 return result; }
boolean containsKey(Object key):如果此映射包含对于指定键的映射关系,则返回 true。
public boolean containsKey(Object key) { return getNode(hash(key), key) != null; } final Node<K,V> getNode(int hash, Object key) //根据hash值和key查找节点 { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { if (first.hash == hash && // 查找第一个节点 ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null) { if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; }
boolean containsValue(Object value):如果此映射将一个或多个键映射到指定值,则返回 true。
public boolean containsValue(Object value) { Node<K,V>[] tab; V v; if ((tab = table) != null && size > 0) { for (int i = 0; i < tab.length; ++i) //外层循环搜索数组 { for (Node<K,V> e = tab[i]; e != null; e = e.next) //内层循环搜索链表 { if ((v = e.value) == value || (value != null && value.equals(v))) return true; } } } return false; }
Set<Map.Entry<K,V>> entrySet():返回此映射所包含的映射关系的Set视图,即返回键值对的集
public Set<Map.Entry<K,V>> entrySet() { Set<Map.Entry<K,V>> es; return (es = entrySet) == null ? (entrySet = new EntrySet()) : es; }
get(Object key):返回指定键所映射的值;如果对于该键来说,此映射不包含任何映射关系,则返回 null。
public V get(Object key) { Node<K,V> e; //通过getNode方法先找到包含该key的节点,再返回节点的value return (e = getNode(hash(key), key)) == null ? null : e.value; }
boolean isEmpty():如果此映射不包含键-值映射关系,则返回 true。
public boolean isEmpty() { return size == 0; }
Set<K> keySet():返回此映射中所包含的键的set视图,即返回键集
public Set<K> keySet() { Set<K> ks; return (ks = keySet) == null ? (keySet = new KeySet()) : ks; }
V put(K key,V value):在此映射中关联指定值与指定键。
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null)//该key的hash值对应的那个节点为空 tab[i] = newNode(hash, key, value, null);//新建节点 else { //节点不为空,先比较链表上的第一个节点 Node<K,V> e; K k; if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) //若该key对应的键值对已经存在,则用新的value取代旧的value { V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } // 若“该key”对应的键值对不存在,则将“key-value”添加到table中 ++modCount; //如果加入该键值对后超过最大阀值,则进行resize操作 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
注意:在JDK1.8中,HashMap的存储结构采用数组+链表+红黑树这种组合型数据结构。当hash值发生冲突时,会采用链表或者红黑树解决冲突,当同一hash值得节点数小于8时,则采用链表,否则采用红黑树。这一改变,主要是提高查询速度。
void putAll(Map<? extends K, ? extends V> m):将指定映射的所有映射关系复制到此映射中,这些映射关系将替换此映射目前针对指定映射中所有键的所有映射关系
public void putAll(Map<? extends K, ? extends V> m) { putMapEntries(m, true); }
V remove(Object key):从此映射中移除指定键的映射关系(如果存在)
public V remove(Object key) { Node<K,V> e; return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value; }
int size():返回此映射中的键-值映射关系数
public int size()
{ return size; }
Collection<V> values():返回此映射所包含的值的Collection视图
//返回“value集合”,实际上返回的是一个Values对象 public Collection<V> values() { Collection<V> vs; return (vs = values) == null ? (values = new Values()) : vs; }
三、HashMap的应用示例代码
public class HashMapDemo { public static void main(String[] args) { HashMap<String, String> hm = new HashMap<>(); System.out.println("调用put函数:"); hm.put("01", "Amy"); hm.put("02", "harry"); hm.put("03", "Gary"); hm.put("04", "Amy"); HashMap<String, String> hm2=(HashMap<String, String>) hm.clone(); System.out.println(hm2); System.out.println("调用clear函数:"); hm2.clear(); System.out.println(hm2); System.out.println("调用containsKey函数:"+hm.containsKey("01")); System.out.println("调用containsValue函数:"+hm.containsValue("Amy")); System.out.println("调用entrySet函数:"); Set<Entry<String, String>> result=hm.entrySet(); for(Entry<String,String> entry:result) { System.out.println(entry.getKey()+":"+entry.getValue()); } System.out.println("调用get函数:"+hm.get("03")); System.out.println("调用isEmpty函数:"+hm.isEmpty()); System.out.println("调用keySet函数:"); Set<String> kr=hm.keySet(); //打印所有的key值 for(String str:kr) { System.out.println(str); } System.out.println("调用remove函数:"); hm.remove("02"); System.out.println(hm); System.out.println("调用size函数:"+"size="+hm.size()); System.out.println("调用values函数:"); Collection<String> vs=hm.values(); for(String str:vs) { System.out.println(str); } } }
运行结果截图如下:

四、HashMap总结
HashMap是一个很有用的集合框架,通过下述三个方法可以分别得到HashMap的键集、值集和键值对集。
键集:Set<K> keySet()
值集:Collection<K> values()
键值对集:Set<Map.Entry<K,V>> entrySet()
以上就是我对于HashMap的总结,由于水平有限,本文并未对HashMap的实现机制做深层次的解析,还在进一步的学习中,共勉!
Java集合系列:


